

Deep Learning in der industriellen Bildverarbeitung: Einfach erklärt
Heute tauchen wir in das spannende Thema Deep Learning in der industriellen Bildverarbeitung ein. In diesem Artikel erklären wir leicht verständlich, wie Deep Learning die Bildverarbeitung in der Industrie revolutioniert, warum es so effizient ist und welche Vorteile es für Ihr Unternehmen bringen kann.
Ausserdem versuchen wir den Unterschied zwischen „künstlicher Intelligenz“ (KI), dem „maschinellen Lernen“ (ML) und dem „Deep Learning“ (DL) zu verdeutlichen. Aufgrund der Popularität in den Medien werden die Begriffe nämlich gerne gleichgesetzt. In der Praxis gibt es da aber schon ein paar Unterschiede. Anhand eines einfachen Beispiels erklären wir die Begrifflichkeiten und Unterschiede, um sie besser zu verstehen. Dran bleiben!!
Künstliche Intelligenz (KI), maschinelles Lernen (ML) und Deep Learning (DL) was ist der Unterschied?
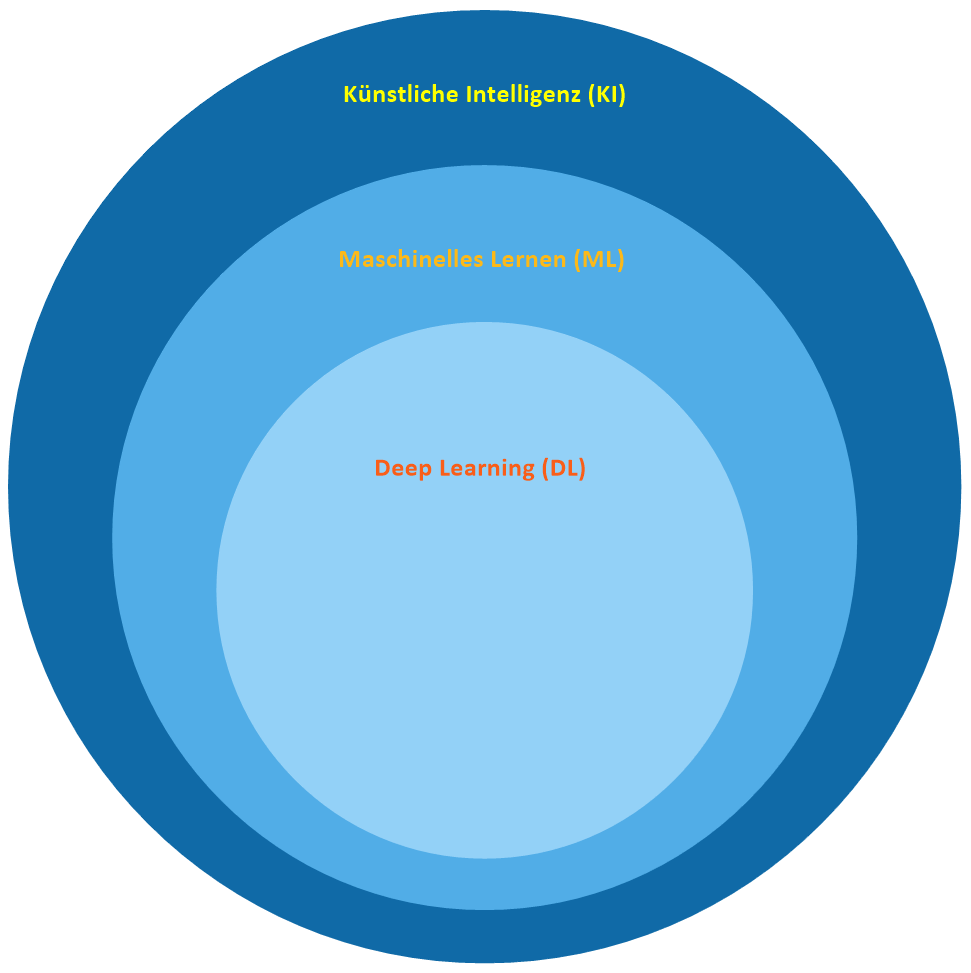
Betrachten wir uns das Diagramm das in vielen Lehrbüchern und im Internet oftmals verwendet wird, können wir erkennen, dass übergeordnet die künstliche Intelligenz (KI) steht und das maschinelle Lernen (ML) und das Deep Learning (DL) scheinbar nur Teilmengen davon sind. Interpretiert man die Grafik ohne gewisse Vorkenntnisse würde man sagen, die künstliche Intelligenz ist das mächtigste Werkzeug und steht über allem. Dann kommt das maschinelle Lernen und als letzte Teilmenge davon das Deep Learning. Nun ja, ganz so einfach ist es nicht und die Grenzen verschwimmen immer schneller. Dennoch hat das Deep Learning einen gewissen Sonderstatus und wird nicht umsonst in vielen Artikeln am häufigsten erwähnt. Beschäftigt man sich intensiver damit, erkennt man, dass das Deep Learning für gewisse Einsatzbereich sogar das mächtigste Werkzeug davon ist.
Definition Künstliche Intelligenz, maschinelles Lernen und Deep Learning
Künstliche Intelligenz (KI): Denk an KI als den großen Regenschirm. Es ist die breite Wissenschaft, Maschinen das „Denken“ beizubringen. Das Ziel der KI ist es, Maschinen zu entwickeln, die Aufgaben erledigen können, die normalerweise menschliche Intelligenz erfordern. Das kann alles Mögliche sein, von der Beantwortung deiner Fragen bis hin zum Fahren eines Autos ohne menschliche Hilfe. Bis es soweit ist, muss der Mensch (Programmierer) aber gewisse Regeln aufstellen und umsetzen (programmieren) z.B. über Entscheidungsbäume und Verknüpfungen im Programm.
Maschinelles Lernen (ML): Unter dem großen KI-Regenschirm ist maschinelles Lernen wie ein starker Ast. ML ist eine Methode, um KI zu erreichen. Statt direkt zu programmieren, wie eine Maschine eine Aufgabe lösen soll, nutzt ML Daten und lernt aus ihnen. Stell dir vor, du zeigst einem Kind viele verschiedene Bilder von Hunden und Katzen. Nach einer Weile fängt das Kind an, zwischen Hunden und Katzen zu unterscheiden, auch wenn es einige zuvor nicht gesehen hat. Das ist im Grunde, was ML macht – es lernt aus Beispielen.
Deep Learning (DL): Deep Learning ist ein Zweig des maschinellen Lernens, noch spezifischer, ein dicker Ast am ML-Ast. DL nutzt etwas, das „neuronale Netze“ genannt wird – eine Struktur, die lose vom menschlichen Gehirn inspiriert ist. Diese neuronalen Netze bestehen aus vielen Schichten (daher „deep“ im Namen), und sie können aus großen Mengen von Daten lernen. DL hat einen enormen Aufschwung erlebt, da es bei komplexen Aufgaben wie Spracherkennung, Bilderkennung und vielen anderen Bereichen erstaunliche Leistungen erbringen kann. Ein Beispiel für DL in Aktion ist die Fähigkeit, ein Bild zu nehmen und zu beschreiben, was darauf zu sehen ist, etwas, das vor nicht allzu langer Zeit wie Science-Fiction klang.
Zusammengefasst: KI ist das große Ziel, maschinelles Lernen ist eine Methode, um dieses Ziel zu erreichen, und Deep Learning ist eine spezielle, sehr leistungsfähige Art des maschinellen Lernens.
KI, ML und DL am Beispiel Erkennung von Hunden und Katzen
Nein, wir wollen jetzt die industrielle Bildverarbeitung nicht dazu mißbrauchen um Hunde von Katzen zu unterscheiden, aber es dient hervorragend dazu die Unterschiede aufzuzeigen und an einem einfachen und für jeden verständlichen Beispiel zu erklären.

Woran erkennt der Mensch einen Hund oder eine Katze?
Die Antworten werden so oder so ähnlich lauten :
- Hat ein Fell
- Zwei Ohren
- Vier Beine
- ….
Trifft das nicht auf beide zu?
Selbst als Mensch haben wir Schwierigkeiten dies in Worte zu fassen bzw. irgendwie zu erklären!!
Wir versuchen es trotzdem einmal mit einfachen Worten für die 3 Verfahren künstliche Intelligenz, maschinelles Lernen und Deep Learning zu erklären.
Künstliche Intelligenz (KI):
In der KI könnte der Ansatz darin bestehen, ein Programm zu schreiben, das explizite Regeln verwendet, um Katzen von Hunden zu unterscheiden. Diese Regeln könnten auf Merkmalen basieren, die leicht zu identifizieren sind, wie die Form der Ohren, die Länge des Fells oder die Größe des Tieres. Ein Ingenieur müsste diese Regeln manuell erstellen und verfeinern, was sehr zeitaufwändig und möglicherweise ungenau für komplexe Bilder wäre.
Nahezu unmöglich, wenn man sich die Vielfalt an Hunden und Katzen anschaut.




Maschinelles Lernen (ML):
Bei einem ML-Ansatz würden wir einem Algorithmus tausende Bilder von Katzen und Hunden zeigen, die jeweils als „Katze“ oder „Hund“ markiert sind. Der Algorithmus würde dann versuchen, Muster in den Bildern zu finden, die konsistent auf eine Katze bzw. einen Hund hinweisen. Nach genügend Training sollte der Algorithmus in der Lage sein, auf einem neuen Bild zu erkennen, ob es sich um eine Katze oder einen Hund handelt, auch wenn er dieses spezielle Bild vorher nie gesehen hat. Hier müssen wir keine spezifischen Regeln definieren – der Algorithmus entwickelt seine eigenen Kriterien zur Unterscheidung.
Aber hier ist etwas Vorsicht geboten!! Je nach der Art und Menge der Bilder die zum Lernen verwendet wurden kann das maschinelle Lernen unbekannte Bilder (Muster) nicht unbedingt korrekt erkennen. Beispiel: Hunderassen und Katzenrassen von denen das ML noch keine Bilder zum Lernen hatte und die z.B. eine andere Fellstruktur und Farbe haben, könnten dann falsch oder gar nicht erkannt (klassifiziert) werden.
Deep Learning (DL):
Deep Learning geht noch einen Schritt weiter. Ein DL-Modell, insbesondere ein tiefes neuronales Netzwerk, würde nicht nur oberflächliche Muster aus den Bildern lernen, sondern auch komplexere Abstraktionen. Zum Beispiel könnte es in den Anfangsschichten des Netzwerks einfache Muster wie Kanten und Farben erkennen und in tieferen Schichten komplexe Merkmale wie Felltextur oder die Pose des Tieres lernen. Deep Learning ermöglicht es, sehr feine Unterschiede zwischen Katzen und Hunden zu erkennen, selbst in Bildern, wo die Tiere in ungewöhnlichen Haltungen sind, teilweise verdeckt oder in schlechter Lichtqualität aufgenommen wurden. Das Besondere an Deep Learning ist, dass es mit zunehmender Datenmenge und komplexeren Netzwerkstrukturen immer bessere Ergebnisse liefert, oft über das hinaus, was mit traditionellen ML-Methoden möglich ist. Es benötigt jedoch erheblich mehr Rechenleistung und Daten, um effektiv zu sein.
Convolutional Neural Networks (CNN): Die Revolution im Deep Learning
Nachdem wir nun festgestellt haben, dass das Deep Learning für Bilder und die industrielle Bildverarbeitung die erfolgversprechendste Methode ist, wollen wir uns nun etwas genauer anschauen, warum dies so ist, wie es im Groben funktioniert und was dahinter steckt. Dabei schauen wir uns zunächst in vereinfachter Form an wie das CNN theoretisch funktioniert, bevor wir uns die praktischen Voraussetzungen anschauen und was dafür benötigt wird.
Was ist ein CNN (Conolutional Neural Network):
Eine der bekanntesten und erfolgreichsten Methoden im Deep Learning ist das Convolutional Neural Network (CNN), auch bekannt als „Faltungsneuronales Netzwerk“. CNNs sind speziell für die Verarbeitung von Bilddaten entwickelt worden und haben in der Bildklassifizierung, wie zum Beispiel der Unterscheidung von Katzen und Hunden und vielen anderen Dingen, bemerkenswerte Erfolge erzielt. Ein CNN ist also eine Klasse von tiefen neuronalen Netzwerken, die Faltungsschichten (Convolutional Layers) beinhalten. Diese Faltungsschichten sind darauf ausgelegt, räumliche Hierarchien in den Daten zu erkennen. Das bedeutet, dass das Netzwerk von einfachen zu komplexeren Merkmalen in den Bildern lernt.
Ich sehe schon die Fragezeichen im Kopf nach dieser doch sehr theoretischen Erklärung zu den CNNs!
Keine Angst es wird gleich verständlicher. Wir wollen ja einfach bleiben.
Wie funktioniert ein CNN – grobe Funktionsweise:
1. Das CNN erhält ein Bild als Eingabe
2. Das Bild durchläuft mehrere Schichten (Layer). Normalerweise sind dies:
- Convolutional Layer: Extrahiert wichtige Merkmale aus dem Bild
- Pooling Layer: Reduziert die Größe und behält wichtige Informationen
- Rectified Linear Unit Layer (ReLu): Entscheidet welche Informationen wichtig sind
- Fully Connected Layer: Trifft die finale Entscheidung
3. Am Ende gibt das Netzwerk eine Klassifikation oder Erkennung aus
Wie funktioniert ein CNN – etwas genauere Funktionsweise (Erklärung der Layer):
1. Convolutional Layer: Extraktion wichtiger Merkmale aus dem Bild
Beispiel: Stell Dir vor, Du hast eine Lupe, die über ein Bild gleitet. Die Lupe sucht nach bestimmten Mustern wie Kanten und Farben. Der Convolutional Layer macht etwas ähnliches – er „gleitet“ über das Bild und erkennt wichtige Merkmale. Aha und was ist jetzt wichtig und was nicht? Nun das entscheidet das Netz dann in den nächsten Schichten (Layern). Da wir viele Bilder verwenden müssen, werden zunächst einmal überhaupt Merkmale wie Kanten, Farbe etc. extrahiert die sichtbar sind.
Merke: Die Lupe gleitet über das gesamte Bild und unterteilt das Bild in gleich große Teilbereiche, nämlich so groß wie die Lupe ist. Durch die Lupe sehen wir also nur einen Teilausschnitt des Bildes. Wie groß dieser ist, hängt vom verwendeten Verfahren des CNNs ab (ja auch da gibt es Unterteilungen bzw. verschiedene CNNs die sich in Feinheiten unterscheiden).
Beispiele für mögliche Merkmale (Features) die der Convolutional Layer extrahiert:






So oder so ähnlich könnten die Merkmale (Kanten, grundlegende Texturen, einfache Formen…….) aussehen, die der Layer in den ersten Ebenen extrahiert. Unser Hunde der Rasse „Magyar Vizsla“ wird sozusagen in einzelne Segmente zerlegt.
Die Merkmalsextraktion erfolgt in den CNNs (Convolutional Layer) also schrittweise über mehrere Ebenen, wobei die Komplexität der erkannten Merkmale zunimmt! Die Ebenen der Merkmale sind dabei in der Regel die folgenden:
Einfache Merkmale (erste Ebenen)
In den ersten Schichten extrahiert das CNN grundlegende visuelle Elemnte:
- Kanten und Linien
- Einfache Formen
- Helligkeitsunterschiede
- Grundlegende Texturen
Beispiel: Ein Filter könnte vertikale Linien extrahieren. Ein anderer horizontale Linien usw.
Mittlere Komplexität (mittlere Ebenen)
In den mittleren Schichten werden komplexere Strukturen erkannt:
- Ecken und Kreuzungen
- Einfache geometrische Muster
- Texturkombinationen
Beispiel: Ein Filter könnte hier rechteckige Formen oder kreisförmige Muster identifizieren.
Komplexe Merkmale (tiefere Ebenen)
In den tieferen Schichten erkennt das CNN hochkomplexe und abstrakte Merkmale:
- Teile von Objekten (z.B. Augen, Nase bei Gesichtern usw.)
- Spezifische Texturen (z.B. Fell, Federn)
- Komplexe Muster und Strukturen
Beispiel: Ein Filter in diesen Ebenen könnte spezifische Gesichtszüge oder charakteristische Merkmale bestimmter Objekte erkennen.
Hierarchische Merkmalsextraktion
Damit wird klar, dass die Merkmalsextraktion in CNNs hierarchisch aufgebaut ist. Auf jeder Ebene werden die Merkmale der vorherigen Ebene kombiniert und zu komplexeren Merkmalen zusammengesetzt. Dies ermöglicht es dem Netzwerk, schrittweise von einfachen visuellen Elementen zu komplexen Objekterkennungen überzugehen.
Die hierarchische Struktur der Merkmalsextraktion macht CNNs besonders effektiv für Bildererkennungsaufgaben, da sie es dem Netzwerk ermöglicht, sowohl lokale als auch globale Merkmale zu erfassen und zu verarbeiten.
Mehr zu den anderen Layern wie Pooling Layer, Rectified Linear Unit Layer und Fully Connected Layer demnächst!!

