

Deep Learning vs. Anomalieerkennung: Fehlererkennung in der industriellen Bildverarbeitung
Stellen Sie sich vor: Ein Kunde kommt mit einer kniffligen Aufgabe auf uns zu. Gemeinsam diskutieren wir, wie wir das Problem am besten angehen. Schnell wird klar, dass herkömmliche Verfahren nicht ausreichen, also schlagen wir vor, für zumindest einen Teil der Aufgabe künstliche Intelligenz zu nutzen. Während wir geduldig erklären, welche KI-Verfahren es gibt, platzt es aus dem Kunden heraus: „Dann nehmen wir die Anomalieerkennung! Wir sind in der Entwicklungsphase eines neuen Produkts und haben sowieso noch keine fehlerhaften Bauteile.“ Und schon beginnt der Erklärungsnotstand 🚨: Anomalieerkennung ist großartig – aber nur, wenn die Bauteile in ihrem Aussehen nahezu identisch sind. Wenn jedes Bauteil anders aussieht, weiß die KI gar nicht, was „normal“ ist, geschweige denn, was ein Fehler sein könnte. Also tief durchatmen 😅, ein Lächeln aufsetzen und die Alternativen erklären…
In der modernen Industrie ist die automatische Fehlererkennung ein entscheidender Faktor für die Qualitätskontrolle. Zwei wichtige KI-basierte Verfahren, die dabei eine zentrale Rolle spielen, sind Deep Learning und Anomaly Detection (Anomalieerkennung). Doch was genau unterscheidet diese beiden Methoden, und wann ist welche Technik sinnvoll einzusetzen? In diesem Blogartikel erklären wir beide Verfahren verständlich und praxisnah. Zunächst nochmals eine allgemeine Erklärung der beiden Verfahren und der jeweiligen Vor- und Nachteile. Danach schauen wir uns dies an einem ganz konkreten Beispiel an.
Was ist Deep Learning? 🤖
Deep Learning ist ein Teilbereich des maschinellen Lernens und basiert auf sogenannten künstlichen neuronalen Netzen. Diese Netze sind inspiriert vom menschlichen Gehirn 🧠 und können große Mengen an Bilddaten analysieren. Deep Learning-Modelle lernen, indem sie viele Beispiele von fehlerhaften und fehlerfreien Produkten sehen. Dadurch erkennen sie selbst komplexe Fehler, die für das menschliche Auge schwer zu identifizieren sind. Mehr dazu auch in diesem Blogartikel.


Praxisbeispiel Automobilindustrie:
Zum Beispiel setzen Automobilhersteller 🚗 Deep-Learning-Modelle ein, um Schweißnähte an Karosserien zu prüfen. Das System erkennt sehr kleine Risse, die für das menschliche Auge nahezu unsichtbar sind, und sortiert fehlerhafte Teile automatisch aus.
Praxisbeispiel Keramikindustrie: Deep-Learning-Systeme ermöglichen die Fehlererkennung auf reflektierenden und spiegelnden Oberflächen, indem sie Dellen und andere Unregelmäßigkeiten sichtbar machen
Vorteile von Deep Learning:
✅ Hohe Genauigkeit bei großen Datenmengen
✅ Erkennung komplexer Muster
✅ Flexibel für verschiedene Anwendungsfälle
Nachteile:
⚠️ Benötigt viele Trainingsdaten
⚠️ Hoher Rechenaufwand
Was ist Anomalieerkennung? 🔍
Im Gegensatz zu Deep Learning muss das System nicht mit vielen fehlerhaften Beispielen trainiert werden. Stattdessen lernt es, wie ein „normales“ (fehlerfreies) Produkt aussieht. Sobald das System etwas Ungewöhnliches erkennt, das von diesem Normalzustand abweicht, meldet es einen möglichen Fehler. Mehr dazu auch in diesem Blogartikel.


Praxisbeispiel: In der Pharmaindustrie 💊 wird Anomalieerkennung zur Qualitätskontrolle von Tabletten verwendet. Das System lernt, wie eine perfekte Tablette aussieht. Tritt eine Abweichung auf – zum Beispiel eine Verfärbung, eine ungewöhnliche Form oder ein kleiner Riss – erkennt das System dies sofort, auch wenn es diesen speziellen Fehler noch nie zuvor gesehen hat.
Vorteile von Anomalieerkennung:
✅ Funktioniert mit wenigen oder keinen fehlerhaften Beispielen
✅ Ideal für seltene oder neue Fehler
✅ Schnell einsetzbar
Nachteile:
⚠️ Kann bei komplexen Fehlern ungenau sein
⚠️ Schwierig, zwischen echten Fehlern und harmlosen Abweichungen zu unterscheiden
Deep Learning vs. Anomalieerkennung: Der Unterschied ⚖️
| Kriterium | Deep Learning | Anomaly |
|---|---|---|
| Datenbedarf | 📊 Viele fehlerhafte & fehlerfreie Daten | 📉 Hauptsächlich fehlerfreie Daten |
| Fehlererkennung | 🔎 Erkennung bekannter Fehler | 🚨 Erkennung unbekannter Abweichungen |
| Flexibilität | 🔄 Sehr flexibel, aber datenintensiv | ⚡ Schnell einsetzbar, weniger flexibel |
| Komplexität | 🧩 Komplexe Muster erkennbar | 🎯 Einfachere Muster erkennbar |
Wann wird welches Verfahren eingesetzt? 🤔
Deep Learning ist ideal, wenn:
✅ viele Daten (Bilder) über bekannte Fehler verfügbar sind.
✅ komplexe Fehler erkannt werden müssen.
✅ hohe Genauigkeit gefordert ist.
Anomalieerkennung eignet sich besonders, wenn:
🔍 Fehler selten oder neu sind.
📊 wenig oder keine Beispiele für Defekte vorliegen.
⚡ schnelle Implementierung benötigt wird.
🚀 Ein real umgesetztes Praxisbeispiel und warum hier nur Deep Learning, aber Anomalieerkennung nicht funktioniert!
Ich denke mit dem folgenden Beispiel, sollte jedem klar werden, warum hier nur der Deep Learning Ansatz mit vielen Beispielen und Fehlern funktioniert. Nachdem nun gewisse Grundlagen besprochen wurden, sollte anhand der nun folgenden Bilder deutlich werden, dass eine Anomalieerkennung hier nicht einsetzbar ist/war. Kurze Erklärung vorab:
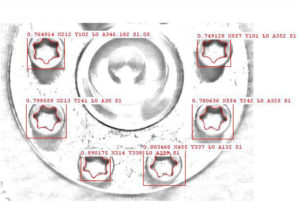
Im folgenden besteht die Aufgabe darin, in einem runden Gussteil mit zwei vertieften Nuten, festzustellen, ob sich darin sogenannte Klemmspäne befinden. Diese Späne können während verschiedener Arbeitsprozesse sich in den Nuten verklemmen und damit die spätere Funktionionstüchtigkeit des Bauteils außer Kraft setzen. Während der Kontrolle wird ein rechtwinkliger Umlenkspiegel in das Gussteil eingetaucht. Aufgrund der Größe des Umlenkspiegels der in die Gussteilbohrung eingetaucht werden kann, deckt dieser nur einen gewissen Teilbereich der gesamten zu detektierenden Nuten ab. Daher wird das Bauteil gedreht und während der Drehung mehrere Aufnahmen gemacht.

Wie man anhand der Beispielbilder von gut Teilen eindeutig erkennen kann, haben wir hier aufgrund der wechselnden Materialeigenschaften des Gussteils ständig wechselnde Bedingungen. In einem solchen Fall würde die Anomalieerkennung bei nahezu jedem wechselnden Glanz- und Hintergrundeffekt einen Fehler melden.
Wie man anhand der Bilder erkennt, kann ein Span jede mögliche Form, Glanzgrad, Größe, Lage usw. haben. In Verbindung mit dem Guss-Hintergrund können Millionen von Variationen entstehen. Ein Einsatz von Anomalieerkennung scheidet, aufgrund der gewaltigen Unterschiede des Gusses bereits innerhalb ein und desselben Bauteils, schon aus. Hier muss ein Deep Learning Ansatz mit vielen Beispielen gewählt werden. In diesem speziellen Fall sind viele gut Teile fast wichtiger wie schlecht Teile. Warum? Aufgrund der erwähnten Gusseigenschaften.
Wie wurde das System trainiert bzw. was war die Vorgehensweise?
- Zunächst einmal wurden Aufnahmen von guten Bauteilen gemacht.
- Im zweiten Schritt wurden handelsübliche Späne die bei jeder spanenden Fertigung entstehen genommen und in die Nuten händisch platziert.
- Daraufhin diese Bauteile mit den Spänen erneut aufgenommen.
- Mit diesem Datensatz erfolgte nun das Labeling der Bilder in gut (ohne Span) und schlecht (mit Span). Hierzu wurden die Späne mit einem Rechteck markiert und einer Klasse zugeordnet.
- Als nächster Schritt erfolgte der Lernvorgang bzw. mehrere Lernvorgänge.
- Aufspielen der Intelligenz auf das Bildverarbeitungssystem vor Ort und Verifikation, dass Bauteile mit zuvor noch nicht trainierten Spänen (unbekannte Fehlerbilder) gefunden wurden.
Anlagendaten:
- Anzahl trainierter Bilder ca. 1200 (verteilt über ca. 350 verschiedene Bauteile)
- Davon NIO Bilder ca. 450
Lernprozess und menschliche Steuerung 🏗️
Wichtig zu verstehen ist, dass weder Deep Learning noch Anomaly Detection (Anomalieerkennung) von Natur aus selbstlernend sind. Beide Systeme müssen zunächst von Menschen trainiert und kontinuierlich überwacht werden. Der Lernvorgang besteht darin, dass Datenexperten die Modelle mit geeigneten Bilddaten versorgen und den Lernprozess steuern. Beim Deep Learning bedeutet dies, dass das Modell mit zahlreichen Beispielen von fehlerhaften und fehlerfreien Produkten gefüttert wird. Bei der Anomalieerkennung hingegen wird das System hauptsächlich mit Bildern von fehlerfreien Produkten trainiert, um ein „Normalbild“ zu erstellen.
Nach dem Training sind die Modelle zwar in der Lage, neue Daten eigenständig zu analysieren, solange sich die Rahmenbedingungen nicht stark ändern, trotzdem kann es passieren, dass sich neue Zustände ergeben und das Bildverarbeitungssystem gewisse Fehler aufgrund der neuen Bedingungen nicht mehr detektiert. Die Systeme passen sich nicht automatisch an neue, unbekannte oder zu starke Veränderungen an. In solchen Fällen müssen Updates und Optimierungen aktiv von Fachleuten durchgeführt werden, indem neue Daten hinzugefügt und das Modell neu trainiert wird. Dies stellt sicher, dass die Fehlererkennung auch bei sich ändernden Produktionsbedingungen zuverlässig bleibt.
Fazit 🏁
Beide Methoden sind leistungsstarke Werkzeuge der künstlichen Intelligenz 🤖. Deep Learning überzeugt durch seine Fähigkeit, komplexe Fehler zu erkennen, während die Anomalieerkennung besonders dann stark ist, wenn es darum geht, unbekannte oder seltene Fehler schnell zu identifizieren, die Bauteile aber nahezu immer gleich aussehen. Oft ist eine Kombination beider Ansätze der Schlüssel zu einer noch besseren Qualitätskontrolle in der industriellen Bildverarbeitung. ✅


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}