Herausforderungen bei der Implementierung von KI-basierter Bildverarbeitung
KI-basierte Bildverarbeitung klingt futuristisch, doch sie ist heute schon fester Bestandteil vieler Branchen – von der Qualitätskontrolle in der Produktion bis zur medizinischen Diagnostik. Aber: Die Implementierung dieser Technologie ist komplexer, als sie auf den ersten Blick erscheint. In diesem Beitrag beleuchten wir die größten Herausforderungen und geben praktische Tipps, wie Ihr eine erfolgreiche Integration umsetzen könnt. Egal, ob Ihr mit einem Systemintegrator arbeitet oder die Lösung selbst einführt – hier findet Ihr nützliche Hinweise, die Euch den Einstieg erleichtern.
Daten sind der Schlüssel zum Erfolg
Die Basis für jedes KI-Projekt ist ein Wort: Daten. Ohne qualitativ hochwertige Daten bleibt auch das beste KI-System ineffizient. Wie man so schön sagt: „Garbage in, garbage out.“ Damit Eure KI-basierte Bildverarbeitung optimal funktioniert, müsst Ihr bereits in der Planungsphase sicherstellen, dass ausreichend relevante Daten zur Verfügung stehen.
Herausforderungen der KI vor der Implementierung
1. Datenmenge – Wie viele Bilder braucht man?
KI-Modelle, insbesondere solche auf Basis von Deep Learning, benötigen eine große Menge an Trainingsdaten. Je nach Anwendung können das hunderte oder sogar tausende von Bildern sein. Die Menge hängt von der Komplexität der Aufgabe ab, wie z. B. der Variation der Objekte oder Szenen, die erkannt werden sollen. Dies ist zugleich auch mit die größte Herausforderung bei der KI-Implementierung. Wo und wie bekomme ich die Menge der benötigten Daten her?
2. Qualität statt Quantität – Was macht gute Daten aus?
Nicht nur die Menge, sondern auch die Qualität der Daten spielt eine entscheidende Rolle. Es sollten möglichst viele unterschiedliche Beispiele der zu detektierenden Fehler oder Qualitätsmerkmale vorhanden sein – und zwar in hoher Auflösung und repräsentativ für die reale Produktionsumgebung. In der Umgangssprache würde man sagen: Die Zustände der Bauteile werden am besten so benötigt, wie sie in der späteren Produktionsumgebung auftreten können.
Datenmanagement vor und während der Integration
Ein gut durchdachtes Datenmanagement ist essenziell, um die Implementierung effizient zu gestalten.
Vor der Integration: Frühzeitige Datenbereitstellung
Sammelt bereits vor der Integration so viele Daten wie möglich. Je mehr Beispiele Ihr habt, desto besser kann das System trainiert werden. Arbeitet eng mit Kunden oder internen Teams zusammen, um sicherzustellen, dass die Daten die Anforderungen der realen Anwendung widerspiegeln. So spart Ihr Zeit und verbessert die Genauigkeit der Ergebnisse.
Während der Integration: Daten sammeln und labeln
Falls der Großteil der Daten erst während der Integration verfügbar wird, kann sich die Implementierungsphase erheblich verlängern. Die Daten müssen zunächst gesammelt, gelabelt und anschließend für das Training verwendet werden. Dies erfordert zusätzlichen Zeitaufwand und kann den Go-Live verzögern. Tipp: Plant ausreichend Zeit für diesen Schritt ein oder versucht, so viele Daten wie möglich vorab bereitzustellen.
Was bedeutet Labeling von Daten in der KI?
Labeling von Daten ist ein zentraler Schritt in der Entwicklung von KI-Modellen. Dabei werden Rohdaten, wie Bilder oder Videos, mit eindeutigen Informationen (Labels) versehen, die dem KI-System helfen, Muster zu erkennen. Zum Beispiel können in der Bildverarbeitung Objekte in einem Foto mit Kategorien wie „Auto“, „Baum“ oder „Straßenschild“ gekennzeichnet werden. Dieser Prozess ist essenziell, damit die KI die Daten korrekt interpretiert und später zuverlässig arbeitet. Effektives Datenlabeling steigert die Genauigkeit des Modells und ist daher ein entscheidender Faktor für den Erfolg jeder KI-Anwendung.
Warum sind Grenzmuster beim Labeling von Daten wichtig?
Beim Labeling von Daten ist es entscheidend, sogenannte Grenzmuster zu berücksichtigen. Diese Muster repräsentieren Fälle, die sich in einem Graubereich befinden – also Daten, die gerade noch als „in Ordnung“ oder „akzeptabel“ eingestuft werden können. In der KI-basierten Bildverarbeitung könnten das z. B. Bauteile mit minimalen Fehlern sein, die noch innerhalb der Toleranz liegen.
Grenzmuster sind besonders wichtig, weil sie die Fähigkeit der KI verbessern, fein abgestufte Entscheidungen zu treffen und zwischen akzeptablen und nicht akzeptablen Szenarien zu unterscheiden. Fehlen diese Beispiele im Trainingsdatensatz, besteht die Gefahr, dass das Modell entweder zu streng (zu viele gute Teile aussortiert) oder zu nachlässig (Fehler nicht erkannt) agiert.
Daher sollte beim Labeling nicht nur auf klare „Gut“- und „Schlecht“-Beispiele geachtet werden, sondern auch auf diese kritischen Zwischenfälle. Eine sorgfältige Auswahl solcher Grenzmuster sorgt dafür, dass das KI-System in realen Anwendungen präzise und verlässlich arbeitet.
Beispiele für Labeling von Daten:




Die richtige Infrastruktur wählen - Cloud vs. lokale Lösungen?


Eine weitere wichtige Frage lautet: Wo und wie wird das KI-System trainiert? Die Infrastruktur spielt eine große Rolle für die Effizienz und die Kosten der Implementierung.
Option 1: Cloud-basierte Lösungen
- Vorteile: Flexibilität, Skalierbarkeit und Zugriff auf leistungsstarke Rechenressourcen.
- Nachteile: Laufende Kosten und potenzielle Datenschutzbedenken.
- Wann sinnvoll?: Wenn große Datenmengen verarbeitet werden müssen oder die Rechenressourcen vor Ort begrenzt sind.
Option 2: Lokale Lösungen (On-Premises)
- Vorteile: Volle Kontrolle über die Daten und keine Abhängigkeit von externen Anbietern.
- Nachteile: Höhere Anschaffungskosten und längere Einrichtungszeit. Während des Lernvorgangs wird der PC oft blockiert, was den Betrieb vorübergehend einschränkt.
- Wann sinnvoll?: Bei sensiblen Daten oder wenn langfristige Kosten niedrig gehalten werden sollen.
Grundsätzliche Fragen die man sich vor der KI-Implementierung daher stellen sollte:
Warum wir lokale KI-Lösungen bevorzugen
Bei der Implementierung von KI-Systemen ziehen wir lokale Lösungen den Cloud-basierten Ansätzen vor. Einer der größten Vorteile ist die volle Kontrolle über die Daten und die eingesetzten Algorithmen. In einer lokalen Umgebung kann man frei entscheiden, welchen Typ von KI-Algorithmus man nutzen möchte – sei es ein neuronales Netz, ein klassisches Machine-Learning-Modell oder eine Kombination aus beidem. Diese Flexibilität ist in der Cloud oft eingeschränkt, da viele Anbieter vorgefertigte Lösungen mit festgelegten Algorithmen anbieten.
Ein weiterer Pluspunkt: Datensicherheit. Da bei lokalen Lösungen die Daten ausschließlich auf eigenen Servern oder Rechnern verarbeitet werden, müssen keine sensiblen Informationen an externe Anbieter übermittelt werden. Das schützt nicht nur vor möglichen Datenschutzproblemen, sondern bietet auch mehr Sicherheit in Branchen, in denen Vertraulichkeit entscheidend ist, wie etwa in der Medizin oder der Produktion.
Für Laien bedeutet das: Mit einer lokalen Lösung behält man die volle Kontrolle – sowohl über die Technologie als auch über die Daten. Man ist nicht auf die Vorgaben eines Cloud-Anbieters angewiesen und kann die KI optimal an die eigenen Anforderungen anpassen. Zwar sind die Anschaffungskosten zunächst höher, aber langfristig zahlt sich diese Investition durch größere Unabhängigkeit und Flexibilität aus.
Welche lokalen KI-Algorithmen können eingesetzt werden?
Bei der Implementierung von KI-basierter Bildverarbeitung stehen verschiedene Algorithmen zur Verfügung, die je nach Anwendungsfall ihre Stärken ausspielen. Einer der bekanntesten und effizientesten Algorithmen ist YOLO (You Only Look Once). Dieser Algorithmus ist speziell für die Echtzeit-Objekterkennung entwickelt worden und bietet einige entscheidende Vorteile gegenüber anderen Methoden wie R-CNN oder SSD. Zusätzliche Informationen zu Deep Learning und Algorithmik findet ihr in diesem Blogbeitrag.
Der größte Vorteil von YOLO liegt in seiner Geschwindigkeit. Während viele Algorithmen das Bild in einzelne Abschnitte zerlegen und diese nacheinander analysieren, betrachtet YOLO das gesamte Bild auf einmal. Das spart enorm viel Rechenzeit, was ihn ideal für Anwendungen macht, bei denen schnelle Entscheidungen gefragt sind – z. B. in Produktionslinien oder bei der Überwachung in Echtzeit. Zudem ist YOLO bekannt für seine hohe Genauigkeit bei der Erkennung und Lokalisierung von Objekten, auch wenn sie sich überlappen.
Im Vergleich zu anderen Algorithmen, die oft komplexere oder ressourcenintensivere Berechnungen erfordern, punktet YOLO durch seine Effizienz und Benutzerfreundlichkeit. Dadurch ist er nicht nur leistungsstark, sondern auch vergleichsweise einfach in bestehende Systeme zu integrieren. Für Anwendungen, die auf schnelle und präzise Bildverarbeitung angewiesen sind, ist YOLO daher eine der besten Optionen.
Wie arbeitet der YOLO-Algorithmus?
Der YOLO-Algorithmus (You Only Look Once) ist eine der effizientesten Methoden für die Objekterkennung. Sein Name deutet bereits darauf hin, wie er funktioniert: Anders als viele herkömmliche Ansätze analysiert YOLO ein Bild in einem einzigen Durchlauf (statt in mehreren Schritten) und erkennt dabei gleichzeitig Objekte und ihre Positionen. Dazu teilt der Algorithmus das Bild in ein Raster auf und berechnet für jede Zelle, ob sich ein Objekt darin befindet, welche Klasse es hat (z. B. Auto, Person, Tier) und wo es sich genau befindet.
Die Kerndaten von YOLO umfassen:
- Echtzeitfähigkeit: Er verarbeitet bis zu 60 Bilder pro Sekunde, was ihn ideal für Anwendungen macht, bei denen schnelle Entscheidungen gefragt sind, wie in der Videoüberwachung oder industriellen Bildverarbeitung.
- Hohe Genauigkeit: YOLO erkennt Objekte präzise, auch wenn sie sich überschneiden oder in komplexen Szenen auftreten.
- Effizienz: Dank seiner Architektur ist YOLO deutlich ressourcenschonender als viele andere Algorithmen und kann auch auf Geräten mit begrenzter Rechenleistung eingesetzt werden.
Durch seine Kombination aus Geschwindigkeit und Genauigkeit ist YOLO eine ausgezeichnete Wahl für Projekte, bei denen Echtzeit-Performance und zuverlässige Objekterkennung im Fokus stehen.
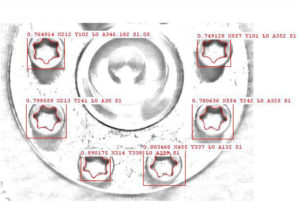
Beispiel einer Bildrasterung durch Yolo

Fazit: Vorbereitung ist alles
Die Implementierung einer KI-basierten Bildverarbeitung ist kein Plug-and-Play-Projekt. Es erfordert sorgfältige Planung, insbesondere in Bezug auf Datenmanagement, die Wahl der passenden Infrastruktur und die eingesetzten Algorithmen. Lokale KI-Lösungen bieten dabei viele Vorteile, da sie die volle Kontrolle über Daten und Algorithmen ermöglichen. Diese Flexibilität erlaubt es, den Algorithmus gezielt auf die jeweilige Anwendung abzustimmen – sei es ein leistungsstarker Echtzeit-Algorithmus wie YOLO, der durch Geschwindigkeit und Genauigkeit überzeugt, oder andere Ansätze, die spezifische Anforderungen besser erfüllen.
Ein weiterer Schlüssel zum Erfolg ist eine frühzeitige Datensammlung, die sowohl klare Muster als auch Grenzmuster enthält, um die KI bestmöglich zu trainieren. Nur so kann das System später präzise Entscheidungen treffen und zuverlässig arbeiten.
Durch eine durchdachte Vorbereitung, die auf die spezifischen Anforderungen Eures Projekts abgestimmt ist, könnt Ihr nicht nur die größten Stolpersteine umgehen, sondern auch die Effizienz und Effektivität der eingesetzten KI-Lösung maximieren. Mit der richtigen Strategie und sorgfältig ausgewählten Technologien schöpft Ihr das volle Potenzial dieser innovativen Technologie aus.
Habt Ihr Fragen zur KI-Implementierung? Schreibt uns in den Kommentaren oder kontaktiert unser Expertenteam!